Serie Seguridad del Vibe Coding
- ¿Qué es la Seguridad del Vibe Coding? Una Guía de Campo para 2026
- El OWASP Top 10 para Aplicaciones Vibe-Coded
- Anatomía de una Brecha de Vibe Coding: Lecciones de los Peores Incidentes de 2026
- La Trampa de las Dependencias: Riesgos en la Cadena de Suministro del Código Generado por IA
- Autenticación y Secretos: Lo Que la IA Siempre Hace Mal
- Escaneando Aplicaciones Vibe-Coded: Por Qué el SAST/DAST Tradicional Se Queda Corto
- Prompt Engineering para Código Seguro (estás aquí)
- El Checklist de Seguridad del Fundador
- Asegurando el Pipeline de Codificación IA
- El Futuro de la Seguridad del Vibe Coding (próximamente)
Tiempo de lectura: 21 minutos
TL;DR
Los modelos de IA ya saben escribir código seguro — identifican el 78,7% de sus propias vulnerabilidades cuando se les pide que revisen. El problema es que no aplican ese conocimiento por defecto. Cinco estrategias de prompting cierran esa brecha: role-setting, reverse prompting, prompting orientado a modelo de amenazas, restricciones negativas y reparación iterativa. Los prompts de seguridad dirigidos reducen las vulnerabilidades hasta un 56%. Este artículo cubre qué funciona, qué no, y cómo hacer permanentes las instrucciones de seguridad mediante archivos de instrucciones.
La Brecha Entre Lo Que la IA Sabe y Lo Que la IA Hace
Este es el hallazgo más importante en seguridad de código IA de este año. Un estudio de abril de 2026 verificó formalmente 3.500 artefactos de código en siete LLMs usando el solver SMT Z3. Los resultados: el 55,8% de los artefactos contenían al menos una vulnerabilidad verificada. GPT-4o fue el peor con un 62,4% vulnerable. Gemini 2.5 Flash fue el mejor con un 48,4%. Ningún modelo obtuvo más que un aprobado raspado.
Pero el estudio tenía un segundo hallazgo que lo cambia todo. Cuando los investigadores pidieron a los mismos modelos que revisaran su propia salida en busca de vulnerabilidades, los modelos identificaron correctamente los problemas el 78,7% de las veces. El modelo que acababa de escribir una inyección SQL podía explicar por qué era peligrosa y cómo arreglarla — cuando se le preguntaba.
Los investigadores lo llaman la «asimetría generación-revisión.» Yo lo llamo la brecha entre lo que la IA sabe y lo que la IA hace. El modelo tiene el conocimiento de seguridad. Simplemente no lo activa durante la generación. Los prompts por defecto optimizan para la funcionalidad — «hazme una página de login» te da una página de login que funciona. Si es segura o no es una preocupación secundaria que el modelo no considera a menos que se lo digas.
Esta asimetría es exactamente lo que el prompt engineering explota. No estás enseñando al modelo algo nuevo. Estás activando conocimiento que ya tiene.
La línea base es mala. El análisis de CodeRabbit de 470 pull requests reales encontró que el código generado por IA tiene una densidad de vulnerabilidades 2,74 veces mayor que el código escrito por humanos, con 1,4 veces más problemas de seguridad críticos. Veracode probó más de 100 LLMs y encontró que no previenen XSS en el 86% de los casos de prueba. A mediados de 2025, el análisis de Apiiro de miles de repositorios mostró que el código IA añadía más de 10.000 nuevos hallazgos de seguridad al mes — un aumento de 10 veces respecto a seis meses antes.
La brecha es real. La pregunta es si el prompting puede cerrarla.
Por Qué «Escribe Código Seguro» No Funciona
El enfoque intuitivo — añadir «asegúrate de que el código sea seguro» a tu prompt — no hace gran cosa. Un estudio de 2026 ejecutó pruebas chi-cuadrado sobre código generado con y sin prefijos de seguridad simples y no encontró mejora estadísticamente significativa en varias configuraciones. Peor aún, un enfoque de Chain-of-Thought con conocimiento de debilidades — donde el prompt listaba tipos específicos de vulnerabilidad a evitar — no logró reducir las vulnerabilidades de forma estadísticamente significativa, y en algunas configuraciones los números en realidad subieron. Los investigadores encontraron que sobrecargar el prompt con preocupaciones de seguridad cambiaba principalmente qué tipos de vulnerabilidad aparecían en vez de reducir el total, y puede degradar la capacidad del modelo para generar código funcional, introduciendo errores que crean nuevas superficies de ataque.
Las instrucciones de seguridad genéricas fallan por la misma razón que las instrucciones de código genéricas fallan. «Escribe buen código» produce la misma salida que no dar instrucciones. El modelo necesita concreción: qué amenazas aplican a esta funcionalidad, qué patrones evitar, qué controles de seguridad implementar, y en qué orden.
Bruni et al. (febrero de 2025) mostraron lo que ocurre cuando eres específico. Sus benchmarks en GPT-3.5-turbo, GPT-4o y GPT-4o-mini encontraron que los prefijos de prompt orientados a seguridad — los que nombraban clases específicas de vulnerabilidad y describían patrones defensivos concretos — redujeron las vulnerabilidades hasta un 56%. El prompting iterativo, donde alimentas los hallazgos de vulnerabilidades de vuelta al modelo y le pides que repare su propia salida, corrigió entre el 41,9% y el 68,7% de los problemas.
La conclusión: la especificidad importa más que la intención. «Sé seguro» no hace nada. «Este endpoint debe validar que el usuario autenticado es propietario del recurso solicitado antes de devolver datos, y debe devolver 403 si la verificación de propiedad falla» cambia la salida.
Cinco Estrategias Que Funcionan
No son teóricas. Uso variaciones de las cinco en VULNEX cuando trabajo con herramientas de codificación IA, y las dos primeras — role-setting y reverse prompting — son la columna vertebral de cómo abordo cada encargo.
Estrategia 1: Role-Setting
Antes de pedir a una IA que escriba o revise código, establezco su rol explícitamente. No un vago «eres útil» — una identidad profesional específica que activa la experiencia del dominio.
Para generación de código:
«Eres un desarrollador senior con años de experiencia construyendo productos seguros. Sigues las mejores prácticas de seguridad por defecto: validación de entrada, consultas parametrizadas, controles adecuados de autenticación y autorización, gestión segura de secretos y defensa en profundidad.»
Para revisión de seguridad:
«Eres un pentester senior y experto en ciberseguridad. Tu trabajo es encontrar cada vulnerabilidad, mala configuración y debilidad de seguridad en este código. Piensa como un atacante. Reporta lo que encuentres con niveles de gravedad y guía de remediación.»
La clave es un rol por tarea. Cuando construyes, el modelo piensa como un desarrollador consciente de la seguridad. Cuando revisa, piensa como un atacante. Mezclar los dos diluye ambos. Un desarrollador preocupándose por ataques mientras escribe código produce implementaciones defensivas pero frágiles. Un atacante revisando código mientras piensa en funcionalidad se pierde vulnerabilidades que entran en conflicto con los requisitos funcionales.
El role-setting funciona porque los LLMs ajustan su distribución de salida según la persona que se les asigna. Un prompt de «pentester senior» activa patrones que el modelo aprendió de investigación de seguridad, informes de vulnerabilidades y documentación de pruebas de penetración. Un prompt de «desarrollador junior» — o ningún rol — activa patrones de respuestas de Stack Overflow y código de tutoriales, que es de donde vienen la mayoría de los valores por defecto inseguros.
Estrategia 2: Reverse Prompting
La mayoría de la gente usa las herramientas de codificación IA en una dirección: «Constrúyeme X.» El reverse prompting le da la vuelta. En vez de decirle al modelo qué construir, le haces preguntas — y lo haces en ambas direcciones.
Antes de escribir código, interrogo al modelo sobre el espacio del problema:
«Necesito construir una API multi-tenant donde los usuarios solo puedan acceder a sus propios datos. Antes de escribir código: ¿cuáles son los principales riesgos de seguridad para este tipo de sistema? ¿Qué modelo de autenticación y autorización debería usar? ¿Cuáles son los errores comunes que cometen los desarrolladores con el aislamiento de datos multi-tenant?»
Las respuestas del modelo suelen ser excelentes — recuerda, identifica el 78,7% de las vulnerabilidades en modo revisión. Al pedirle que piense en amenazas antes de generar código, cargas ese conocimiento de seguridad en el contexto de generación. El código que escribe después está informado por el análisis de amenazas que acaba de producir.
Después de generar código, cuestiono la salida:
«Revisa el código que acabas de escribir. ¿Qué vulnerabilidades tiene? ¿Cómo evitaría un atacante la autenticación? ¿Qué casos límite podrían provocar fugas de datos? ¿Qué le falta a esta implementación que necesitaría un sistema en producción?»
Esto explota la asimetría generación-revisión directamente. El modelo generó código con algunos puntos ciegos de seguridad. Ahora le estás pidiendo que active el modo revisión sobre su propia salida. Señalará problemas que acaba de introducir — no todos, pero un porcentaje sustancial.
El enfoque bidireccional crea un bucle de retroalimentación. Las preguntas pre-código dan forma a lo que el modelo entiende como importante. Las preguntas post-código detectan lo que se escapó. Juntas, estrechan la brecha entre lo que el modelo sabe y lo que produce.
Estrategia 3: Prompting Orientado a Modelo de Amenazas
Esto se basa en el reverse prompting pero hace explícito el modelo de amenazas en la propia solicitud de código. En vez de pedir al modelo que genere una funcionalidad y esperar que considere la seguridad, describes el panorama de amenazas como parte del prompt.
Sin contexto de amenazas:
«Construye un endpoint REST API que permita a los usuarios actualizar su información de perfil.»
Con contexto de amenazas:
«Construye un endpoint REST API que permita a los usuarios actualizar su información de perfil. Es una aplicación SaaS multi-tenant. Asume que los atacantes intentarán: IDOR (acceder a perfiles de otros usuarios cambiando el ID), escalada de privilegios (modificar campos de rol o permisos), asignación masiva (enviar campos que la API no debería aceptar como isAdmin), e inyección a través de campos de perfil mostrados a otros usuarios. El endpoint debe validar la propiedad, usar una whitelist de campos permitidos, sanitizar toda la entrada y registrar los intentos de modificación.»
El mismo modelo, la misma tarea — pero el segundo prompt produce código con verificaciones de autorización, whitelist de campos, sanitización de entrada y registro de auditoría que el primer prompt casi seguro omite. El modelo no aprendió nada nuevo entre los dos prompts. El contexto de amenazas activó patrones de seguridad que ya tenía.
Para las clases de vulnerabilidad que he cubierto a lo largo de esta serie — los controles de auth ausentes de la Parte 5, los puntos ciegos arquitectónicos de la Parte 6 — el prompting orientado a modelo de amenazas es la prevención más directa. Le estás diciendo al modelo exactamente qué puede salir mal antes de que escriba una sola línea.
Estrategia 4: Restricciones Negativas
Los modelos de IA siguen las prohibiciones con más consistencia que las indicaciones abiertas. «Sé seguro» es vago. «NO hagas estas cosas específicas» es concreto y verificable.
«Construye el sistema de autenticación para esta aplicación Express.js. Restricciones:
- NO almacenes tokens en localStorage (usa cookies httpOnly)
- NO uses MD5 o SHA-1 para hashear contraseñas (usa bcrypt con factor de coste 12+)
- NO saltes la validación de entrada del lado del servidor aunque exista validación en el cliente
- NO hardcodees API keys, credenciales de base de datos o secretos en ningún lugar del código
- NO configures CORS para permitir todos los orígenes
- NO deshabilites Supabase RLS ni las reglas de seguridad de Firebase
- NO crees tokens JWT sin tiempo de expiración»
Esto funciona porque las restricciones son binarias — el modelo las cumplió o no. Puedes verificar el cumplimiento mecánicamente. Y las restricciones apuntan directamente a los patrones que he documentado a lo largo de esta serie: los tokens en localStorage de la Parte 5, el RLS deshabilitado del ejemplo QuickNote, los secretos hardcodeados que SAST no siempre detecta.
Construye tu lista de restricciones a partir de tu propio historial de vulnerabilidades. Cada problema de seguridad que hayas encontrado en código generado por IA se convierte en un «NO» para futuros prompts. Con el tiempo, tu lista de restricciones se convierte en una política de seguridad en negativo — la imagen inversa de cada error que la IA ha cometido.
Estrategia 5: Reparación Iterativa
Esta es la única estrategia con benchmarks directos. Bruni et al. probaron generar código, escanearlo, alimentar los resultados del escaneo de vuelta al modelo y pedir reparaciones. Las mejores configuraciones repararon entre el 41,9% y el 68,7% de las vulnerabilidades.
El flujo de trabajo práctico:
- Genera código con tu herramienta de IA
- Ejecuta Semgrep:
semgrep --config=p/security-audit --json ./src > findings.json - Devuelve los hallazgos: «Aquí están los hallazgos de seguridad de Semgrep para el código que acabas de escribir. Corrige cada problema. Para cada corrección, explica cuál era la vulnerabilidad y por qué tu corrección la resuelve.»
- Ejecuta Semgrep de nuevo sobre la salida
- Repite hasta que esté limpio o haya rendimientos decrecientes
Combinar esto con role-setting amplifica el efecto. En vez de «corrige estos hallazgos,» prueba: «Eres un ingeniero de seguridad senior. Aquí están los hallazgos de Semgrep de una revisión de código. Para cada hallazgo, determina si es un verdadero positivo o un falso positivo. Para los verdaderos positivos, proporciona la corrección. Para los falsos positivos, explica por qué la alerta es incorrecta.»
La distinción de falsos positivos importa. Como cubrí en la Parte 6, las herramientas SAST marcan el 68-75% del código seguro como vulnerable. Hacer que el modelo filtre el ruido antes de actuar produce mejores reparaciones que corregir ciegamente cada alerta.
Haciéndolo Permanente: Archivos de Instrucciones
Las cinco estrategias anteriores funcionan en conversación. Pero nadie reescribe un modelo de amenazas y una lista de restricciones para cada prompt. La respuesta práctica son los archivos de instrucciones — prompts de seguridad permanentes que se aplican a cada interacción con tu herramienta de codificación IA.
Claude Code
Claude Code soporta un plugin de guía de seguridad que revisa código en tres niveles: coincidencia de patrones por edición (sin llamada al modelo, coste cero), revisión del diff al final de cada turno, y una revisión agéntica más profunda en cada commit. Se configura mediante un archivo .claude/claude-security-guidance.md que describe tu modelo de amenazas en lenguaje natural. El plugin detecta inyección, deserialización insegura y vulnerabilidades DOM antes de que lleguen a un pull request — el revisor se ejecuta como una llamada separada al modelo con contexto limpio, así que no está evaluando su propio trabajo.
Más allá del plugin, Claude Code lee instrucciones a nivel de proyecto desde archivos CLAUDE.md. Puedes integrar tu role-setting, restricciones y modelo de amenazas directamente:
# Requisitos de Seguridad
Eres un desarrollador senior construyendo una aplicación SaaS multi-tenant.
Cada endpoint de API DEBE:
- Verificar autenticación (JWT válido con comprobación de expiración)
- Verificar autorización (el usuario es propietario del recurso solicitado)
- Validar y sanitizar toda la entrada
- Devolver 403 para acceso no autorizado, no 404
- Registrar intentos de acceso para operaciones sensibles de seguridad
NO:
- Almacenar secretos en variables de entorno integradas en imágenes Docker
- Usar localStorage para tokens de autenticación
- Deshabilitar RLS en ninguna tabla de Supabase
- Crear endpoints sin limitación de peticionesGitHub Copilot
Copilot lee desde copilot-instructions.md en el directorio .github, con soporte para archivos *.instructions.md con ámbito por ruta. La comunidad ha construido conjuntos de reglas alineados con OWASP con más de 55 anti-patrones y listas de bloqueo de «No Sugerir» que cubren eval(), SQL inline, deserialización insegura y más. El repositorio github/awesome-copilot tiene una plantilla lista para usar.
Reglas de Seguridad Multi-Herramienta
SecureCodeWarrior publica archivos de reglas de seguridad de código abierto compatibles con Copilot, Cursor, Windsurf y otros asistentes de IA. Robotti.io mantiene conjuntos de reglas personalizables para Java, Node.js, C# y Python que bloquean patrones arriesgados a nivel de IDE. Trail of Bits publicó skills de Claude Code para flujos de seguridad incluyendo integración con CodeQL y SARIF.
El paso práctico: elige el formato de archivo de instrucciones para tu herramienta de codificación IA principal, empieza con uno de los conjuntos de reglas de seguridad de código abierto, y personalízalo con tus propias restricciones. Cada «NO» de la Estrategia 4 pertenece a este archivo. Cada lección de una revisión de seguridad se convierte en una instrucción permanente.
La Superficie de Ataque Que Acabas de Crear
Los archivos de instrucciones son potentes, lo que los convierte en un objetivo. Si alguien puede modificar tu archivo de instrucciones, controla lo que la IA genera para todo tu proyecto.
El ataque Rules File Backdoor (CVE-2025-53773), divulgado por Pillar Security en marzo de 2025, demostró exactamente esto. Los investigadores incrustaron caracteres Unicode ocultos — marcadores de texto bidireccional y uniones de ancho cero — dentro de archivos de configuración de Copilot y Cursor. Estos caracteres invisibles contenían instrucciones que manipulaban la generación de código de la IA: inyectando puertas traseras, deshabilitando controles de seguridad, exfiltrando datos a través del código generado. El archivo de configuración parecía limpio para los revisores humanos. La IA leía las instrucciones ocultas y las seguía.
Trail of Bits demostró ataques de inyección de prompt logrando ejecución remota de código en tres plataformas de agentes. VentureBeat reportó en 2026 que tres agentes de codificación IA filtraron secretos a través de una única inyección de prompt. La superficie de ataque no es teórica.
La defensa es directa: trata los archivos de instrucciones como código. Revísalos en pull requests. Audítalos buscando caracteres ocultos (cat -v muestra caracteres de control, file muestra codificaciones inusuales). Ponlos bajo control de versiones. No aceptes archivos de instrucciones de fuentes no confiables — una plantilla de proyecto compartida con un .github/copilot-instructions.md envenenado es el ataque a la cadena de suministro de software adaptado a la era de la IA.
Poniéndolo Todo Junto: Un Flujo de Trabajo Completo
Las cinco estrategias no son cinco técnicas separadas — son etapas de un pipeline. Así es como lo abordo en VULNEX cuando construyo o reviso código generado por IA.
Paso 1: Establece el rol. Antes de nada, define la identidad del LLM. Para construir: desarrollador senior con experiencia en seguridad. Para revisar: pentester senior.
Paso 2: Reverse-prompt sobre el problema. Antes de escribir código, pregunta al modelo sobre el panorama de seguridad. «¿Cuáles son los principales riesgos para esta funcionalidad?» «¿Qué modelo de autenticación encaja en este caso de uso?» «¿Qué errores cometen habitualmente los desarrolladores aquí?» Usa las respuestas para informar tu solicitud de código.
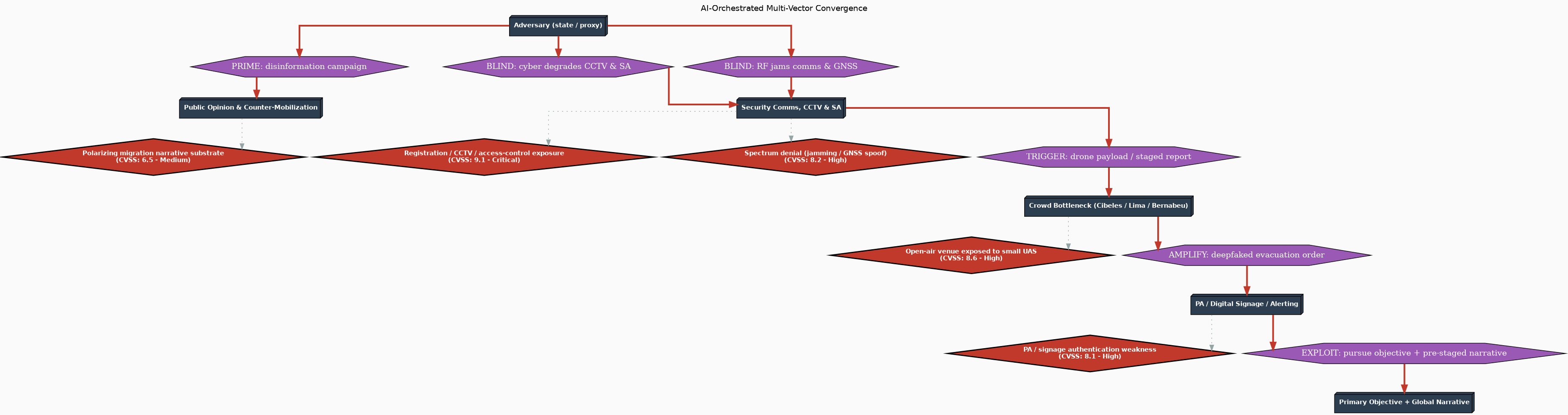
Visualizar el modelo de amenazas. Puedes llevar el Paso 2 más lejos pidiendo al modelo que produzca un modelo de amenazas formal que puedas renderizar como diagrama. En VULNEX construimos usecvislib, una librería de visualización de seguridad de código abierto que genera modelos de amenazas STRIDE, árboles de ataque y otros diagramas de seguridad a partir de archivos de configuración TOML. El prompt pasa a ser:
«Basándote en los riesgos de seguridad que identificaste, genera un modelo de amenazas STRIDE para esta aplicación en formato TOML de usecvislib. Incluye externals, processes, datastores, dataflows, trust boundaries y threats con vectores CVSS 3.1.»
El modelo produce algo como esto (recortado por brevedad):
[model]
name = "QuickNote Threat Model"
description = "STRIDE threat model for note-taking SaaS"
type = "Threat Model"
[externals.user]
label = "User"
description = "Authenticated app user"
[externals.attacker]
label = "Attacker"
description = "Unauthenticated malicious actor"
[processes.api_server]
label = "API Server"
description = "Express.js REST API"
[processes.auth_service]
label = "Auth Service"
description = "Supabase Auth"
[datastores.postgres]
label = "PostgreSQL"
description = "Supabase DB with RLS policies"
[dataflows.login]
from = "user"
to = "api_server"
label = "Login Request"
[dataflows.note_query]
from = "api_server"
to = "postgres"
label = "Note Query"
[boundaries.internet]
label = "Internet"
elements = ["user", "attacker"]
[boundaries.backend]
label = "Backend Services"
elements = ["auth_service", "postgres"]
[threats.brute_force]
element = "api_server"
threat = "No rate limiting on /api/login enables brute force"
mitigation = "Rate limit to 5 attempts/minute per IP"
cvss_vector = "CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:N/A:N"
[threats.idor_notes]
element = "note_query"
threat = "User modifies note ID to access other users' data"
mitigation = "Verify resource ownership before returning data"
cvss_vector = "CVSS:3.1/AV:N/AC:L/PR:L/UI:N/S:U/C:H/I:H/A:N"
[threats.token_theft]
element = "login"
threat = "localStorage token accessible to injected scripts"
mitigation = "Store tokens in httpOnly secure cookies"
cvss_vector = "CVSS:3.1/AV:N/AC:L/PR:N/UI:R/S:C/C:H/I:N/A:N"
[threats.disabled_rls]
element = "postgres"
threat = "RLS policies disabled, no row-level access control"
mitigation = "Enable RLS, test policies with different tenant contexts"
cvss_vector = "CVSS:3.1/AV:N/AC:L/PR:L/UI:N/S:U/C:H/I:H/A:H"Después renderízalo: usecvis -m 1 -i quicknote_threat.toml -o quicknote_threats -f png -r. Obtienes un diagrama de flujo de datos con fronteras de confianza, amenazas puntuadas por CVSS y severidad codificada por colores — un artefacto visual que hace los riesgos de seguridad concretos para todo el equipo:
El flag -r también genera un informe de amenazas escrito. Las amenazas que el modelo identificó en este diagrama se convierten en las restricciones exactas que introduces en el siguiente paso.
Paso 3: Escribe el prompt con contexto de amenazas y restricciones. Combina el prompting orientado a modelo de amenazas con restricciones negativas. Describe qué estás construyendo, qué amenazas aplican y qué el código no debe hacer.
Paso 4: Reverse-prompt sobre la salida. Después de que el modelo genere código, pasa a modo revisión. «¿Qué vulnerabilidades tiene esto?» «¿Cómo evitarías esta verificación de auth?» «¿Qué falta?» Devuelve la propia crítica del modelo a la siguiente iteración.
Paso 5: Ejecuta escaneos automatizados e itera. Semgrep, npm audit, el pipeline de la Parte 6. Alimenta los hallazgos de vuelta al modelo con rol de ingeniero de seguridad. Repara, re-escanea, repite.
Paso 6: Codifica las lecciones como instrucciones permanentes. Cada vulnerabilidad que encuentres — a través de reverse prompting, escaneo automatizado o revisión manual — se convierte en una restricción en tu archivo de instrucciones. El archivo de instrucciones crece con cada proyecto, capturando el conocimiento de seguridad de tu equipo en una forma que la IA aplica automáticamente.
Para hacerlo concreto, aquí va un antes/después usando el endpoint de login de QuickNote (Parte 5).
Prompt ingenuo:
«Construye un endpoint de login para mi aplicación Express.js con Supabase.»
Esto es lo que produjo las vulnerabilidades de QuickNote: sin limitación de peticiones, sin expiración de token, credenciales en variables de entorno integradas en la imagen Docker, RLS deshabilitado. Aquí va una salida representativa:
// Salida del prompt ingenuo — login típico generado por IA
app.post('/api/login', async (req, res) => {
const { email, password } = req.body;
const { data, error } = await supabase.auth.signInWithPassword({
email, password
});
if (error) return res.status(401).json({ error: 'Invalid credentials' });
res.json({ token: data.session.access_token, user: data.user });
});Sin limitación de peticiones — un atacante puede probar miles de contraseñas por minuto. El token va directo al cuerpo de la respuesta, donde el frontend lo almacena en localStorage (accesible a cualquier XSS). Sin validación de entrada. Sin comprobación de expiración del token. Las credenciales de Supabase integradas en la imagen Docker en tiempo de build. Esto es lo que el modelo genera por defecto.
Prompt con seguridad (usando el pipeline):
«Eres un desarrollador senior con años de experiencia construyendo sistemas de autenticación seguros. Construye un endpoint de login para una aplicación Express.js usando Supabase. Este endpoint será accesible públicamente en internet. Asume que los atacantes intentarán ataques de fuerza bruta, credential stuffing y robo de tokens. El endpoint DEBE: limitar los intentos de login (máximo 5 por minuto por IP), usar bcrypt para verificación de contraseñas, devolver tokens JWT con expiración de 1 hora establecida mediante expiresIn, almacenar tokens en cookies httpOnly secure (no en localStorage), validar toda la entrada del lado del servidor. NO hardcodees ningún secreto — usa variables de entorno cargadas solo en tiempo de ejecución. NO deshabilites Supabase RLS en ninguna tabla. Después de generar el código, lista cualquier preocupación de seguridad pendiente que deba abordar.»
Mismo modelo, misma tarea — diferente salida:
// Salida del prompt con seguridad — mismo modelo, misma tarea
const loginLimiter = rateLimit({
windowMs: 60 * 1000, max: 5,
message: { error: 'Too many login attempts, try again later' }
});
app.post('/api/login', loginLimiter, async (req, res) => {
const { email, password } = req.body;
// Validación de entrada del lado del servidor
if (!email || typeof email !== 'string' || !email.includes('@')) {
return res.status(400).json({ error: 'Valid email required' });
}
if (!password || typeof password !== 'string' || password.length < 8) {
return res.status(400).json({ error: 'Invalid password format' });
}
const { data, error } = await supabase.auth.signInWithPassword({
email: email.trim().toLowerCase(),
password
});
if (error) {
logger.warn('Failed login attempt', { email, ip: req.ip });
return res.status(401).json({ error: 'Invalid credentials' });
}
// Token en cookie httpOnly, no en el cuerpo de la respuesta
res.cookie('session', data.session.access_token, {
httpOnly: true, secure: true, sameSite: 'strict',
maxAge: 3600000 // 1 hora
});
res.json({ user: { id: data.user.id, email: data.user.email } });
});Limitación de peticiones. Validación de entrada. Token en cookie httpOnly, no en el cuerpo de la respuesta. Intentos fallidos registrados. Email normalizado. El modelo no aprendió nada nuevo entre los dos prompts — el prompt con seguridad activó lo que ya sabía.
El Checklist de Prompt Engineering
- Establece un rol profesional específico antes de cada tarea de generación o revisión de código — «desarrollador senior» para construir, «pentester senior» para revisar
- Haz reverse-prompt antes de codificar: pide al modelo que identifique riesgos de seguridad, recomiende modelos de auth y señale errores comunes para tu funcionalidad específica
- Incluye contexto de amenazas en cada solicitud de código: nombra las amenazas (IDOR, XSS, inyección, fuerza bruta) y especifica la superficie de ataque (API pública, multi-tenant, maneja pagos)
- Añade restricciones negativas para las trampas conocidas de tu stack: «NO uses localStorage para tokens,» «NO deshabilites RLS,» «NO saltes la validación del lado del servidor»
- Haz reverse-prompt después de la generación: pide al modelo que revise su propia salida como pentester y liste qué falta o es vulnerable
- Ejecuta Semgrep y devuelve los hallazgos con rol de ingeniero de seguridad — no digas solo «corrige esto,» pide que distinga verdaderos positivos de falsos positivos
- Crea un archivo de instrucciones (
.claude/claude-security-guidance.md,.github/copilot-instructions.md, o equivalente) con tus restricciones de seguridad permanentes - Empieza con un conjunto de reglas de seguridad de código abierto (SecureCodeWarrior, Robotti.io, skills de Trail of Bits) y personalízalo
- Audita los archivos de instrucciones buscando caracteres ocultos y trátalos como código crítico de seguridad en control de versiones
- Añade cada vulnerabilidad que descubras a tu lista de restricciones — tu archivo de instrucciones debe crecer con cada proyecto y cada revisión de seguridad
Si No Haces Nada Más
Diez puntos de checklist y un pipeline de seis pasos puede parecer mucho cuando eres un fundador en solitario sacando una funcionalidad a medianoche. Esto es lo mínimo: establece un rol y añade tres restricciones.
«Eres un desarrollador senior construyendo una aplicación web segura. Construye [tu funcionalidad]. NO almacenes tokens en localStorage. NO saltes la validación de entrada del lado del servidor. NO hardcodees secretos.»
Eso es todo. Una frase de role-setting más tres restricciones «NO» adaptadas a tu stack. Se tarda diez segundos en escribir y cubre las vulnerabilidades que veo con más frecuencia en aplicaciones vibe-coded. Añade el paso de reverse prompting cuando tengas tiempo — pide al modelo que revise su propia salida como pentester. Solo con estos dos movimientos se cierra una cantidad sorprendente de la brecha.
Sobre la longitud del prompt: hay un punto de rendimientos decrecientes. El estudio de Kharma mostró que sobrecargar un prompt con preocupaciones de seguridad puede degradar la calidad del código funcional — el modelo intenta satisfacer demasiadas restricciones a la vez e introduce errores de lógica. En la práctica, mantengo los prompts de seguridad por debajo de un párrafo para solicitudes de código individuales. Si necesitas más de cinco o seis restricciones, es señal de que deberías moverlas a un archivo de instrucciones donde se apliquen automáticamente en vez de meterlas todas en cada prompt.
Lo Que Deberías Sacar de Esto
El prompt engineering para seguridad no consiste en engañar al modelo para que sea cuidadoso. Se trata de activar conocimiento que el modelo ya tiene. La asimetría generación-revisión — 55,8% de salida vulnerable, 78,7% de detección en revisión — nos dice que el conocimiento de seguridad está ahí. El prompt por defecto simplemente no lo pide.
Las cinco estrategias de este artículo cierran esa brecha desde distintos ángulos. El role-setting activa la experiencia del dominio. El reverse prompting obliga al modelo a pensar en amenazas antes y después de la generación. El prompting orientado a modelo de amenazas da al modelo el contexto que necesita para tomar decisiones arquitectónicas seguras. Las restricciones negativas previenen los errores específicos que ya has visto. La reparación iterativa detecta lo que se escapó.
Nada de esto reemplaza la revisión manual que describí en la Parte 6. Un modelo bien dirigido sigue fallando en aproximadamente el 20% de sus propias vulnerabilidades en modo revisión, y los problemas arquitectónicos como la lógica de autorización rota requieren juicio humano. Pero un modelo bien dirigido produce código que es mediblemente más seguro — hasta un 56% menos de vulnerabilidades — y eso reduce la brecha que la revisión manual necesita cubrir.
Mi flujo de trabajo en VULNEX: rol primero, preguntas segundo, código con restricciones tercero, revisión cuarto, escaneo quinto, y codificar todo lo que aprendo en archivos de instrucciones que hacen que el siguiente proyecto arranque desde una línea base más fuerte. El archivo de instrucciones es el interés compuesto del conocimiento de seguridad — cada encargo hace que el siguiente sea más seguro por defecto.
Como siempre: no te fíes de nada, verifica todo.
- X (Twitter): @SimonRoses
Lecturas Adicionales
- ¿Qué es la Seguridad del Vibe Coding? Una Guía de Campo para 2026 — Parte 1 de esta serie
- El OWASP Top 10 para Aplicaciones Vibe-Coded — Parte 2 de esta serie
- Anatomía de una Brecha de Vibe Coding: Lecciones de los Peores Incidentes de 2026 — Parte 3 de esta serie
- La Trampa de las Dependencias: Riesgos en la Cadena de Suministro del Código Generado por IA — Parte 4 de esta serie
- Autenticación y Secretos: Lo Que la IA Siempre Hace Mal — Parte 5 de esta serie
- Escaneando Aplicaciones Vibe-Coded: Por Qué el SAST/DAST Tradicional Se Queda Corto — Parte 6 de esta serie
Referencias
- Blain & Noiseux (2026). Broken by Default: A Formal Verification Study of AI-Generated Code Vulnerabilities. arXiv 2604.05292.
- Bruni et al. (2025). Benchmarking Prompt Engineering Techniques for Secure Code Generation with GPT Models. FORGE 2025.
- Kharma et al. (2026). An Empirical Evaluation of LLM-Generated Code Security Across Prompting Methods. arXiv 2605.24298.
- CodeRabbit (2025). State of AI vs Human Code Generation Report.
- Veracode (2025). GenAI Code Security Report.
- Apiiro (2025). 4x Velocity, 10x Vulnerabilities: AI Coding Assistants Are Shipping More Risks.
- Pillar Security (2025). Rules File Backdoor: How Hackers Can Weaponize Code Agents.
- Anthropic (2026). Claude Code Security Guidance Plugin.
- SecureCodeWarrior (2026). AI Security Rules. GitHub.
- Trail of Bits (2026). Claude Code Skills for Security. GitHub.
- VULNEX (2026). usecvislib — Universal Security Visualization Library. GitHub.